Programming Languages
Defined:
A collection of primitives, building blocks through which algorithms are represented, and rules indicating how these primitives can be combined. Each primitive has its own syntax and semantics (i.e. symbols and meanings).
Why is it important?
Programming is the act of creating a program, encoding it into machine readable form, and inserting it into the machine. We use programming languages as a way of representing algorithms as programs. A machine, as many people know, understands string of 0’s and 1’s. However, it is error prone and tedious to write programs in such a way. Therefore, modern programming languages are used because they are more human readable, faster to write, and less error prone because they are easier to read by humans. When the program is read by the computer, it goes through a process that turns the human readable program into the machine’s language.
Programming languages themselves are written in a way that makes it possible to represent algorithms in a variety of ways. Some use a sequence of steps, others use predefined processes, while other still treat everything as components that all communicate in order to achieve an end result. Each of these languages cause the programmer to think about the process differently. Some are better at representing financial calculations, some are better for web development, others are specifically built for searching and sorting optimisation.
In order to build anything, you need to use appropriate tools. Sure you can connect pieces of wood together with glue to build a toy car. But using glue to bind boards together to build a house may not be the best idea. Similarly, if we limit our understanding of languages, we also limit the tools with which we can build software that is intended to be used for a specified reason.
Compiled vs Interpreted:
When a program is translated into machine language, it is sometimes translated and stored for later use. This is known as compiling. However, some languages are considered interpreted because they are translated at the time that they are being used. That is, instead of translating the program for later use, it is translated (interpreted) at the time of use.
Pseudo Code:
A notational system in which algorithms can be informally represented.
Programming Paradigms:
Imperative (Procedural): Algorithms are expressed as a sequence of commands that, when followed, manipulate data to produce a desired result.
Declarative Programming: Applies a pre-established, general purpose, problem solving algorithm. The programmer defines a precise statement of the problem rather than the algorithm. E.g. a meteorologist doesn’t have to create an algorithm; it is already known. He or she only specifies the weather model and allows the simulation algorithm to produce a result.
Logic Programming: Uses inference rules in order to derive a result.
Functional Programming: Programs accept inputs and produce outputs just as a function does in mathematics. Programs are made up of smaller programs where one program’s output is the input for another program.
Object Oriented Programming: The software system is viewed as a collection of objects (units that perform actions that ate related to itself and request actions from other objects).
Program Anatomy:
In general, a program consists of a collection of statements that fall into one of three categories: Imperative statements (steps to be performed), declarative statements (customized variables), or comments (enhances readability).
Language Examples:
FORTRAN (FORmula TRANslator): Still widely used for scientific and engineering applications. It started as an imperative programming language but has evolved throughout the years. Today’s FORTRAN is much different than it was when it was first introduced and contains many object oriented features.
COBOL (Common Business –Oriented Language): Developed by the U.S. Navy for business applications
Ada: Developed by the Department f Defense as a single, general purpose programming language. Started out as an imperative language, but later versions have incorporated object oriented concepts.
C: An imperative language originally designed for developing system software.
C++: Created as an enhanced version of C compatible with the object oriented paradigm.
C#: Developed by Microsoft for the .NET framework in order to customize specific features of C++ without concern for current standards or proprietary rights.
Java: An object oriented language, derived from C and C++, and designed to be implemented universally. A program written in Java can be executed efficiently over a wide range of machines. Java also has a vast number of templates available which makes implementing complex software relatively easy.
Prolog (PROgramming in LOGic): Declarative based on repeated resolution (a technique for deriving consequences from a collection of statements). E.g. the teacher is either in class or sick. The teacher is not in class. Therefore the teacher must be sick.
Organization and Architecture
Bus:
A collection of wires that connects the CPU and main memory in order to transfer bit patterns. The CPU reads data or writes data to main memory by supplying the address in main memory to access, a signal indicating that a read or write operation is needed, and the data to store (if writing data). Other devices (e.g. video cards, modems, monitors) are also connected to the bus in order to communicate with the machine.
Mother Board:
The computer’s main circuit board.
RAM (Random Access Memory):
Volatile memory that is stored in cells that are usually 8 bits. Also called Main Memory. This is the memory that is used when a program is executing. So the more RAM you have the more space you have for programs to execute. Imagine if you wanted to access a program that used 2 GB of RAM and another that used another 2 GB of RAM. What if your computer only had 3 GB of RAM? The RAM would constantly be swapped out as each program was being executed. Today’s programs are becoming more and more complex and therefore are using more and more memory in order to execute them.
ROM (Read-Only Memory):
A special, nonvolatile, portion of the computers main memory where the CPU expects to find its initial program. This, bootstrap, program fetches the operating system from disk storage and loads it into main memory. Additionally, the computer’s Basic Input/Output System (BIOS) is stored in ROM. This is the collection of software routines for performing fundamental input/output activities (e.g. receiving keyboard input, displaying messages to the screen, reading data from mass storage devices). Since these routines are available before the operating system is fully loaded, they allow the machine to communicate with the user and report errors during bootstrapping.
Peripherals:
A computer must be able to move data in and out of the system. In order to do so, it uses devices that are attached to it collectively known as peripherals (e.g. keyboard, monitor, mouse).
Flash Memory:
Many mass storage devices (e.g. DVD, Magnetic Disc) require the use of physical motion in order to read or write data. However, flash memory allows the machine to send electronic signals directly to the storage medium where they cause electrons to be trapped in tiny chambers of silicone dioxide. Even though flash memory is able to store elections for many years, repeated erasing slowly damages the silicone dioxide chambers. This is why it is not used for general purpose main memory where data is overwritten many times a second. Flash memory, unlike magnetic or optical systems, is also not sensitive to shock. So it is widely used for portable devices that allow reasonable restrictions to data alterations (e.g. cameras, cell phones).
CPU (Central Processing Unit):
Usually referred to as the “processor” or “microprocessor,” due to its small size. This is the brains of the computer. It controls the manipulation of data in the computer and is connected to the machine’s man circuit board (i.e. mother board) via pins and sockets.
Mass Storage:
Less volatile, secondary storage, that is usually able to be removed from the machine (e.g. flash drive, CD, DVD). These usually require mechanical motion and, therefore, require more time to read and write data.
Clock Speed:
Clock speed is commonly used to compare machines. A computer’s clock us a circuit called an oscillator. This circuit generates pulses that are used to coordinate the machine’s activities. Clock speeds are measured in hertz (Hz) with one Hz equal to one cycle (pulse) per second. Unfortunately, different CPU designs may perform different amounts of work in a single clock cycle. So speed alone is not useful in comparing different CPUs. Executing the same program on each machine (i.e. benchmarking) is more reliable when comparing different CPUs.
Operating Systems
- Bridge between the hardware and the software
System Software vs Application Software
There are two broad categories that encompass a machine's software, application software and system software.
Application software consists of software that performs a machine's utilization tasks such as spreadsheets, database systems, desktop publishing systems, games, etc.
System software performs tasks that are common to computer systms in general (e.g. the infrastructure that the application software requires).
System software can be further segmented into two categories:
- Operating system
- Utility software
Utility software mostly consists of software for performing fundamental installation tasks that are not part of the operating system
By implementing certain activities as utility software, the system can be customized to the needs of a particular installation.
Operating System Components
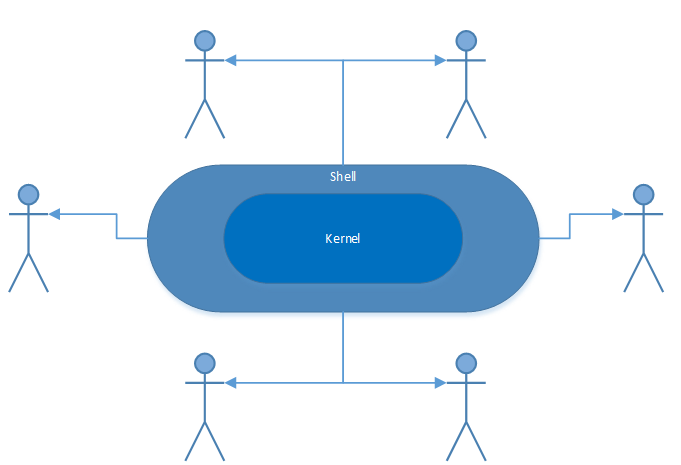
Kernel:
Internal part of the OS that contains the software components to perform the basic functions (e.g. File Manager, Device Drivers, Memory Manager, Scheduler, Dispatcher)
Shell:
Portion of the OS that handles communication with users
Starting Up
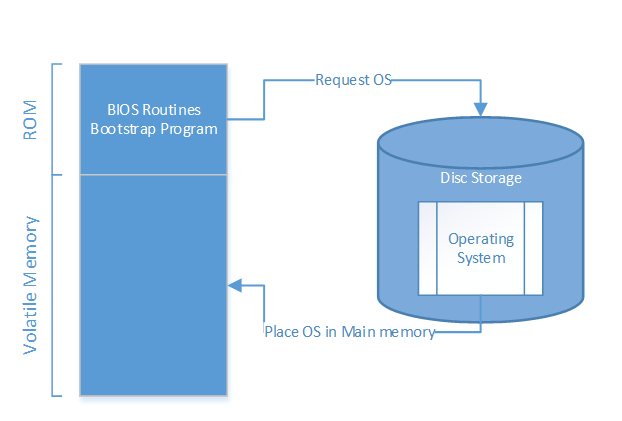
Booting:
The process of transferring the OS from mass storage into memory. Bootstrap program is stored in ROM in many systems. Today, there are a number of systems storing programs permanently in main memory (i.e. Turnkey).
BIOS:
Collection of software routines stored in ROM that perform fundamental input/output, reading data from mass storage, etc. Allows for the system to operations before the operating system becomes functional.
Running
Program vs Process
A program is a static set of directions while a process is the dynamic activity or running a program and has properties that can change over time. The current status of the process is known as the "process state."
Time Sharing and Multitasking
In modern operating systems, where there are multiple processors or CPU time is divided into intervals, multiple users and/or multiple programs can run simultaneously. In older operating systems, various processing methods were implemented but many would restrict the machine to running a single program at a time or even restrict the user from interacting with the running program at all.
A complexity that this introduces is that the system must dynamically allocate tasks to various processors so that they are all used efficiently (i.e. load balancing).
Operating systems with multiple processors must also break tasks into smaller subtasks compatible with the number of processors; this is known as scaling.
Semaphore
In order to split the time allocated to a processor, there needs to be some way of identifying a process as being used. Typically a flag is set called a semaphore (in reference to the railway signals used to control access to sections of track).
A semaphore is used to indicate that a specific piece of code can only be run by one process at a time; this is known as a "critical region." Before the code begin to execute, the flag is set and any other critical region will not be able to run until the flagged critical region is released.
While it is sometimes necessary to block certain code from running by multiple processes (e.g. a printer being used by two processes may have strange results), a "deadlock" can occur if two or more processes are blocked because they are all waiting for a resource that is allocated."
Software Testing
Bugs are a part of software development:
Typically, early programmers deal with syntax errors while more seasoned programmers deal with errors in logic. That isn't to say that a beginning programmer will not deal with logic problems, only that more experienced programmers tend to have less issues with syntax.
Logical errors are harder to spot than syntax errors, especially since a developer's tools tend to help find syntax errors by highlighting and failing to compile. On the other hand, compilers and IDEs cannot determine if your logic will resolve the issue at hand.
While it is every programmer's intention to write error free code, it is nearly impossible to test every angle and execution path. Therefore most commercially available software is shipped with known bugs.
That being said, there are different levels of error and some bugs are critical enough to stop a release while others are bugs that can be resolved in a later release.
Testing vs Debugging
Testing is the activity of finding out whether a piece of code (method, class, program, etc.) produces the intended behaviour. Debugging is the attempt to pinpoint and fix the source of an error. Both of these skills are crucial for quality software products, and the techniques used for each have a large amount of overlap.
One way of looking at testing and debugging is: Testing is how we find the errors while debugging is how we figure out why the error is happening so that we can resolve the issue.
When Does Testing Begin?
Testing can begin long before an application is complete. Once a piece of code is written and compiled (or not depending on the language), it can be tested. Early testing allows us to see problems early on and mix them at a much lower cost to the project. It also allows us to learn from experiences during development which can allow developers to side step issues rather than repeating the same mistakes. Additionally, it allows the development team to have repeatable tests that can be used to test for errors that have inadvertently been introduced during other development.
When is Testing Complete?
In order to deliver a quality product, we need to ensure that there are no errors in the product. As you will discover, several tests must be written for any one component. Therefore the amount of testing far exceeds the amount of development for an application. Many projects have a Backlog of additional work to be completed in the future, even on “Go Live.” These facts allow us to say two things about testing regarding the completion of testing:
- Testing is done when the budget or time runs out for the project.
- Testing continues as users are using the software and submit enhancement requests and identify bugs.
Testing Guidelines
How many Tests?A class that includes a data structure and a method to show the data stored in the data structure. This component should be tested for various things that include but are not limited to:
- Testing data retrieval against a full data structure
- Testing data retrieval against an empty data structure
- Testing data retrieval against a specific data element that exists
- Testing data retrieval against a specific data element that does not exist
Boundaries
Boundaries are often where things go wrong in a system. Boundary tests are created to test the extreme inputs of a system; a stress test. E.g. maximum values, minimum values, etc. In our example above regarding retrieving information from a data structure, the boundary to test would be the inputting of data into the data structure.
Positive vs Negative Tests
Positive tests allow us to test things that we expect to succeed, while negative tests exists to ensure that things that should fail actually do. Many inexperienced testers focus on positive tests and neglect to test the negatives. Negative tests to only ensure that something that is expected to error actually does, but it does so in a usable manner.
Testing and Debugging Techniques
- Unit Testing
- Test Automation
- Manual Walkthroughs
- Print Statements
- Debuggers
Unit Testing
Unit Testing is the testing of individual components of an application and can vary in size (e.g. method, class, group of classes). The focus for unit testing is on verifying that the product is being build right. During development the developer must constantly test his or her code in order to ensure that it is doing what he or she is intending it to do. Single methods are compiled and run with expected outcomes. Likewise classes and objects are tested as components of the system in order to ensure they are performing as expected. Unit tests focus on the internal processing logic and data structure in a component and can be conducted alongside other components being tested. Unit tests should be designed to uncover errors relating to erroneous calculations, comparisons, and data flow. Data flow testing should be established have a priority above any other test. If data do not enter and leave the system as expected, all other tests are disputable. When possible, global data impacts should be documented.
Boundary Testing
This is a very important aspect of Unit Testing and deserves the attention that I am giving it. There it’s stuck in your head that THIS is important. Execution often fails on or near its edges (e.g. an array’s first add and last removal, loops encounter an expected end). Data structures, process flow, and data values should be tested at their edges in order to uncover errors. Unit tests can and should be generated prior to implementation. Doing so will allow the developer to ask questions, clarify what is to be developed, and establish an expected set of results to test against. During this time, design reviews can also be performed in order to ensure a quality framework is in place.
Test Automation
As mentioned in a previous section, a single unit of code or system requires multiple tests to be created and run periodically. This is very time consuming and expensive to the project. Many IDEs today have Test Project Templates available, but these are just programs that allow you to create tests for the rest of the project and easily interact with its members. From that statement, we can see that an automated test is really just a program that runs predefined tests or components and interactions within the system.
Regression Testing
Regression Testing refers to the testing of the system already in place to ensure that a new component or sub-system has not introduced additional issues. Since it does run multiple tests throughout the system, automating this is key to actually doing it; can you imagine testing everything in the system manually every time a change is made? In a basic example, a program is created where every method is written to represent a single test capturing the steps to run it manually. Our example is not without its faults. As it currently stands, we are running tests but we still have to evaluate the results manually. True automation will also evaluate the results. This is done in many ways by many different IDEs. The most basic form of evaluation is to tell the tester that something passed or failed.
Assertions
Assertions are expressions that state a condition expected to be true. If the assertion is false, it failed. In our previous example: An assertion for the retrieving of a specific index in the data structure would be the value expected to be retrieved. If the value was what we expected (assertion of 9 let’s say), we pass. If the value was something else (say g), we fail. Actually, we would fail on two accounts here. First, because it is not 9. Second, because it’s not a number.
Fixtures:
A Fixture is a set of objects in a defined state that will serve as the basis for a unit test. Using our previous example, we can see that we will be populating the data structure every time we need to test the retrieval of data. We also may need some additional classes and objects to connect to a database in order to perform that task. A fixture allows us to setup the system before running the test that we are actually interested in.
Manual Walkthroughs
This is a testing and debugging technique that is relatively underused. It may be the fact that it takes you away from coding, or that the tester isn’t using a fancy tool, or maybe it’s just not seen as valuable to newer testers.
Manual walkthrough includes two different concepts.
- Not everything should be automated
- Leaving the computer behind allows for a different perspective
First, not everything is appropriate for automated testing or to be tested by a program. While it may be possible to test for a specific layout, content clarity, etc. it may take more time to automate those tests than to run them manually. Therefore certain tests need to be run manually in order to spare precious resources and deliver a product on time and on budget. If a tester were to automate or code for some of these tests, he or she would not have the time to work on tests that could and should be done as a program and / or automated.
Second, printing out the actual code and walking through the flow and identifying object interaction with paper and pencil allows you to step into a different mindset and allows the tester to attack the problem from a different angle.
Manual walkthroughs in the second fashion, should be done on smaller pieces of code (e.g. sub systems, single methods, class interaction, etc.). Verbally walking through the code and its interactions is also very helpful and taps into another learning style. Finally, it is of the utmost importance to record the state of every object and structure while going through this process. This can be accomplished in any way that works for the tester (e.g. table, cards, etc.). Many teams today have incorporated code reviews into their development processes. This is a form of manual walkthrough, but should not replace a tester’s use of this technique.
Print Statements
This may be the most widely used technique for testing and debugging. Annotating methods with print statements is very handy because a print statement usually exists in any language and is usually available to everyone. However, it is possible to add too many print statements and make it hard to locate the information you are looking for (say in a loop). It can also be tedious to remove the print statements once they have been used. Then, later, they may be desired again and have to be re-added. Sometimes it is helpful to use a “debug” flag in your code with print statements living inside of conditional statements that check for the debug flag. That all depends on the environment and language that you are coding in though.
Debuggers
A debugger is a software tool used to step through segments of code in real time. Typically, a breakpoint (marker in the code) is set and, once the process reaches that point in execution, the debugger will halt the process and allow the tester to “step through the code” (i.e. allow the user to execute the code line by line). The tester evaluates the state of the process while the debugger keeps track of the state of the executing program. Most debuggers today also have a wide range of other features as well (e.g. step over, step out, record steps).
Error Handling
What is it?
Errors come in all sorts of flavors. If something goes wrong, it is an error. That could be a lot of things:
- The solution to a problem was wrong; you built the product right, but not the right product.
- An object might be used incorrectly (i.e. the program asked an object to execute a method that does not exist)
- The context in which the object is being used is not consistent with the way in which it was designed.
Defensive Programming
Because we know that no program is perfect, we need to code against the assumption that our code may not be used as intended. Objects are most vulnerable when parameters are passed to its initialization method. Therefore, it is important to check the values of everything that comes in. Imagine an object had a data structure that was populated on initialization and thus expected to always have data in it. What would happen if the object was used for something else in the future or it was decided that we should have a way to clear the data set and not repopulate? Ideally, an error is detected by the system. Once the error is met, it is important to notify someone. The message format would vary based on the object and the context in which it is being used. It may read by human eyes or sent back to the client. This information (e.g. success flag, thrown exception) can then be used to determine what to do in the client code.
Exception Throwing
This is the best way to communicate to the client that an error has occurred. Exceptions allow an object to pass information to another object. If the server object throws an exception, the client object must handle it or the process will terminate. Exceptions usually come in a variety of types (e.g. null pointer, invalid type). Developers can, however, create their own custom exceptions.
Testing the Exception
Throwing an exception is also something we want to design correctly and analyse for quality assurance. Exceptions usage should follow the following guidelines:
- Errors should be descriptive
- Errors should be readable
- Errors should contain information that identifies where the error occurred
- Errors should express what actually happened using the appropriate type
Stack Trace
As a process is running, a stack of information is piling up about the current state of the application. When an exception happens, that information is available in a stack trace. When throwing an exception, it is important to know what the method you are using does. In C#, for example, “throw” will preserve the original stack trace while “throw ex” will throw the original exception and reset the stack trace (i.e. destroy the history). “Throw new Exception(ex.Message)” is even worse; it creates a brand new exception which loses the stack trace as well as the original exception’s type (e.g. IOException). Additionally, you lose any information passed as parameters on the original exception.
Try Catch Finally Blocks
Try Catch blocks allow us to “Try” to run through a process and “Catch” the exception if something happens. These should be used often but not everywhere. The rule here is to use one unless you think you don’t actually need one. The “Finally” block allows us to ensure that a piece of code will run regardless of an exception being thrown. This is a great place to close any database connections or perform other code cleanup and release resources.
Error Recovery
In order to recover from an error, we need to know about it. The first step is catching the error. Inside the Catch block, there should be an attempt to resolve the issue and retry. The recovery may not be successful, so in order to protect against an infinite loop, an escape route must be built in (e.g. MAX_ATTEMPTS). It is also possible to avoid errors altogether. But this takes collaboration amongst developers or even teams. For example: a developer may create a way for a consuming process to identify the ability to call a method enabling the calling process to handle the error before it happens.
Testing Strategies
A software testing strategy is a road map that provides the steps to be performed, when they are to be planned, when they are to be performed, how much time, how much effort, and how many resources should be required. The strategy should be flexible so that it can adapt to the changes in development and requirements. However, it should also have a stable structure to enable reasonable planning and management.
Any testing strategy should include:
- Test Planning
- Test Case Design
- Test Execution
- Data Collection and Evaluation
Even the best strategy will fail if the system itself is flawed. Therefore, it is important to consider several issues as part of a successful project:
- Requirements are well defined
- Testing objectives should be explicitly stated
- User groups are well defined
- Rapid testing should be used in a sandwich approach (top down and bottom up)
- Software should be designed for testability
- Formal technical reviews should be performed before testing
- Testing strategies should be evaluated and updated regularly
Validation vs Verification
Verification answers the question of whether you are building the product right.
Validation answers the question of whether you are building the right product.
Validation and Verification (V&V) is an overarching topic that includes development testing, usability testing, qualification testing, installation testing, algorithm analysis, performance monitoring, formal technical reviews, configuration audits, documentation review, and database review. All of these topics are important in validating that the right product is being delivered and it is done right.
The Tester
Psychology of a Tester:
Developers are engineers. And just like any engineer, they are builders. On the other hand, testers are a special group of engineers who have a focus on taking the construct apart. In fact, evidence shows that some people are innately good at debugging while others are not. This makes sense when you think about the skill set that makes a god tester; not everyone likes brain teasers and taking things apart.
Independent Tester:
Developers are constantly testing their own code in order to ensure its completeness and expected use and functionality. However a new set of eyes will see the code in a different way and not have the attachment that the developer has. One way to think of this is a builder building something and that he or she has to break. It is more likely, even though unintended, that the developer will create tests that showcase the program rather than destroying it. It is for this type of reason that an independent tester should be involved and work directly with the developer in order to test for and correct errors. Ideally the independent tester would have no stake in the project aside from testing.
Test Types
Unit Tests – Component Level (e.g. Class, Method, Sub-system)
Integration Tests – Integration with Existing Systems and Sub-systems
Validation Tests – Functionality and Content Testing
System Tests – Environmental Tests (e.g. uptime, performance)
Regression Testing – Re-testing the system once a new piece of code is introduced
Application Testing – Daily end-to-end testing that does not need to be exhaustive but covers the critical path of the application
Unit Tests
(See above)
Integration Tests
The best approach to integration testing is to test incrementally rather than waiting until the entire program is completed. As testing is conducted, the tester should identify critical modules that address several requirements, have a high level of control, are error prone or complex, or have high performance requirements. These critical modules should be tested as early as possible and be included in all regression tests.
Top-Down Approach:
Using a top-down approach we can integrate all components on a major control path (i.e. depth-first) or integrate all components in a given subordinate structure (i.e. breadth-first).
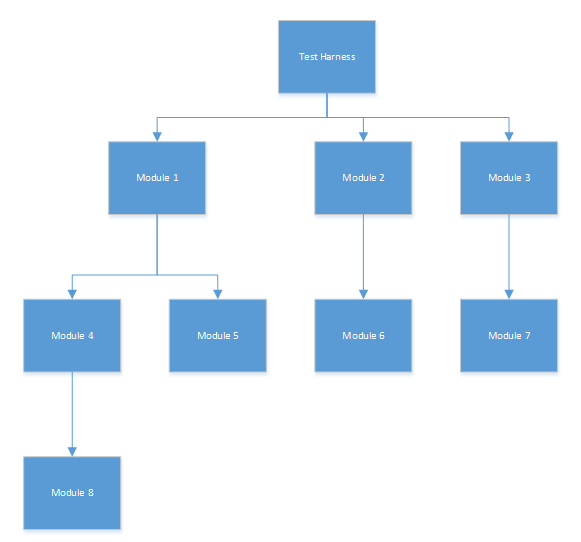
This approach verifies major control and decision points early which can simplify development and testing later on.
The process itself has five steps:
- A test-harness is created and used and stubs are created for all direct subordinates
- Depending on the strategy chosen (breadth-first or depth-first), stubs are completed one-by-one
- Tests are conducted as each component is integrated
- On completion of each set of tests, another stub is replaced
- Regression testing is done when necessary
Bottom-Up Approach:
A bottom-up approach eliminates the need for stubs because processing required for components subordinate to any level is always available. It also reduces the need for separate test harnesses which simplifies testing as the project continues.
The process itself has four steps:
- Low-level components are joined into clusters (i.e. builds) that perform specific functions
- A test harness is written to coordinate test case input and output
- The cluster is tested
- Test harnesses are removed and clusters are combined moving the program structure
Documentation
Test Plan – Describes the overall strategy (e.g. User interaction, data manipulation, display processing, database management, development overhead, start and end dates for each phase, test environment description, special hardware requirements, testing tools defined and techniques, etc.)
Test Procedure – Procedure required to accomplish the test plan (e.g. order of integration, tests to be run at each step, list of all tests and expected results, etc.)
Test Report – History of actual tests performed and their results
System Analysis and Design
System Analysis and Design
Distributed Systems
Distributed Systems
SDLC
SDLC
Security
Authorization
Authentication
User Privileges allow a system to be restricted so that only specified users can access the system itself or specified features and functionality. Typically, privileges are implemented using a username and password combination. In addition to a username and password combination, modern systems are incorporating 2nd and 3rd step authentication which requires the user to enter a special pin number, an automatically generated sting of characters, or some other additional information.
Other possibilities also exist to restrict access to systems and features as well. These include IP addresses, MAC addresses, amongst other options.
User Types
Administrators are usually the highest ranking user. These users have access to anything and everything. A good practice on any machine is to only use the administrative account as needed and to always use an account with less permissions.
Least privileged access
Least privileged access refers to a way of implementing authorization checks so that a user who has multiple roles within a system is only granted access based on his or her least privileged account. In other words, a user should only have enough access to accomplish the task. Doing so increases security of data as well as the system as a whole. It can also help discover bugs as users may experience unexpected issues with software when their privileges are not at an elevated level.
Passwords
Passwords are an essential part of security. With today's technology, it is important to use strong passwords and change them often. It is also important to not use the same password for everything.
Passwords like a person's house number, dog's name, or other easily identifiable information are (as suggested) easier to crack than passwords without meaning. However, one should also take into account the options available for a password and in determining its strength.
Simple Example: A password with 2 letters from the English language, not special characters, and no numbers would have only 676 options(26 * 26). However a password that has a minimum of 8 characters from the English language is significantly more secure (26 * 26 * 26 * 26 * 26 * 26 * 26 * 26 = 208,827,064,576).
Even though the second, more secure example, seems like a large number, a computer can try various options extremely fast. The faster the computer attempting to crack the password, the more tries per second.
Other good practices are to use acronyms rather than real words, including special characters, lower-case and upper-case letters, and numbers.
Types of Attacks
Malware
Malware is an umbrella term used to describe a number of potential types of malicious software. These malicious programs can do a number of bad things to us including: deleting files and installing other software. The following list is only a portion of common types of malicious software.
- Virus - Require some form of interaction to infect a user's device.
- Trojan Horse - Hidden part of some, otherwise, useful software.
- Worm - Can enter a device without any explicit user interaction.
- Sniffing Software (i.e. spyware) - Software that collects data and sends it back to the bad guys.
Spoofing
IP Spoofing allows a person to masquerade as someone you trust by injecting a false source address into information that is sent you the target.
Denial of Service
Denial of Service (DoS) attacks render a systems, networks, etc. unusable to a legitimate user.
These tend to fall into three major categories:
- Vulnerability Attacks - specific messages (in a particular order) are passed and cause a process on the host system to stop or crash the entire system
- Bandwidth Flooding - Sending so much information to the host that the host's access link becomes clogged which prevents legitimate information from reaching the server.
- Connection Flooding - The attacker opens a large number of connections to the host which prevents it from accepting legitimate connections.
Web Based Attacks
Cross Site Scripting (XSS)
Cross Site Scripting is an injection attack that is used to run malicious code. Malicious code can be used to access cookie information, session tokens, or other information retained by the victim's browser.
Cross Site Request Forgery (CSRF)
Cross site request forgery allows a browser to perform unwanted actions on a trusted site.
SQL Injection (SQLi)
This attack injects database queries into data-driven applications.
Session Hijacking
In order to communicate with a web server, a user must send a token that identifies him or her so that the web server knows who requested data or where to send a response. Session hijacking allows a malicious program or user to compromise this token.
Physical Prevention
Privacy Screens
As a user is working in public, he or she may be entering sensitive data (e.g. passwords) or be displaying information that should be kept secure (e.g. legal documents, social security numbers, medical record numbers). A privacy screen is a filter that masks the computer screen from wide angles, so a malicious person would need to be behind the user rather than being able to see the screen from the side.
Laptop Locks
While working at a client site or in a public place, using a laptop lock adds extra physical security by making it harder for a malicious person to physically steal the machine itself.
Password Storage
Storing passwords on sticky notes attached to your computer monitor, in your wallet, under your keyborad, etc. is never a good idea and is something I have encountered al too often.
Whenever possible, a password should be memorized.
Lately, there is a trend toward using a password vault to store your passwords. This is a sound decision for having to store multiple passwords and allows you to only have to remember a single password. That password must be kept secret and be very strong so that a malicious user cannot access all of your passwords.
Disconnect
There may be times when your actions can be performed without the use of the internet or any other network. If a user disconnects from the internet, data cannot be transmitted to a remote system that is outside of the local network. If the local network is not trusted, disconnecting from that as well can also add extra security.
Encryption
Public Key
RSA
Key Fob
Secure Socket Layer (SSL)
Protection
Firewall
Proxy Server
Spam Filters
Anti Virus
Ethics
Ethics
Networking
Networking
Source Control
Source Control
Deployment
Deployment